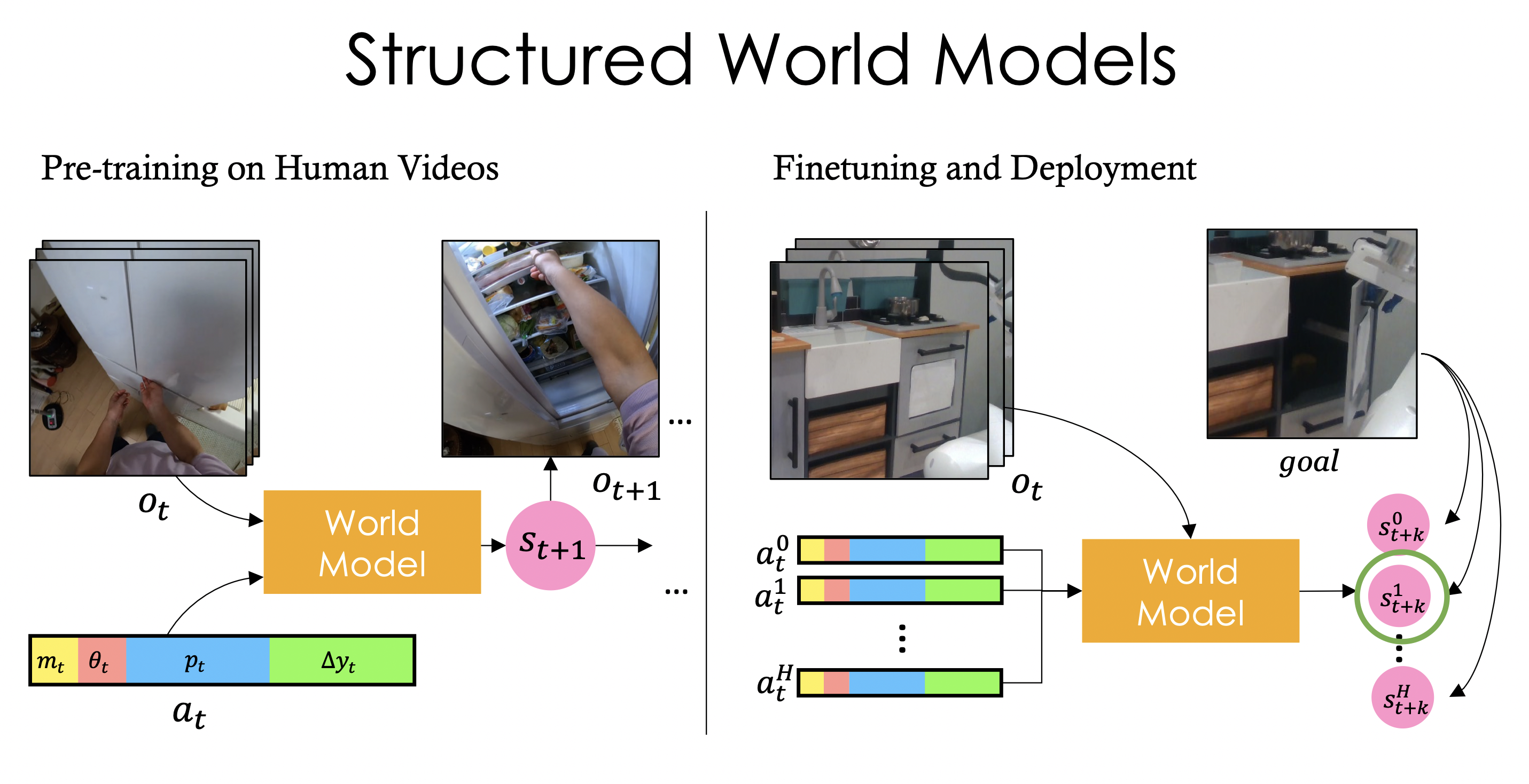
Our approach involves 3 steps -
#1 : Pre-training a world model on human videos,
#2 : Finetuning the world model on unsupervised robot data, and
#3 : Using the finetuned model to plan to achieve goals